Облачный мониторинг серверов Prometheus & Grafana из коробки
-
Готовая система контроля производительности серверов, баз данных и веб-сервисов.
Подключение инфраструктуры за 2 минуты к независимому внешнему кластеру без затрат на развертывание и администрирование собственной системы мониторинга.
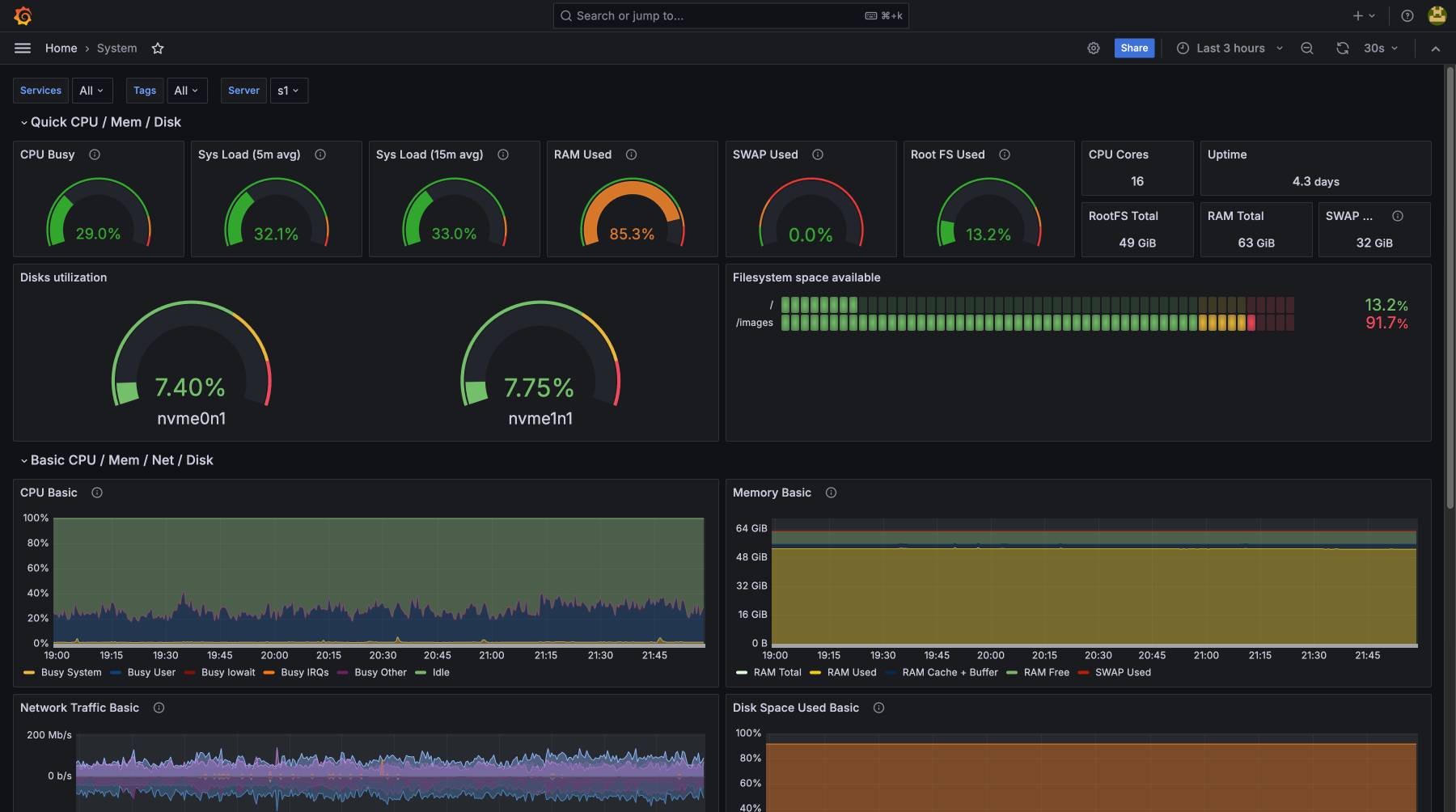
Почему облачный мониторинг HostAdmin надежнее локального?
Полная независимость (Out-of-band):
Если на целевом сервере пропадет сеть, отключится питание или откажет гипервизор, локальный агент мониторинга не сможет отправить уведомление. Наш внешний кластер, расположенный в изолированном облаке, фиксирует прекращение отправки метрик в течение секунд и мгновенно присылает критический алерт в Telegram.
Нулевая нагрузка на сервер (Zero Overhead):
Сбор, индексация, хранение временных рядов (TSDB) и визуализация метрик в Grafana требуют значительных ресурсов CPU и дисковой системы (I/O). При использовании нашего SaaS-решения вся тяжелая аналитическая работа происходит на стороне облачного кластера HostAdmin. Ваши серверы отдают только сырые метрики, сохраняя 99.5% ресурсов для работы основных бизнес-приложений.
Готовая инфраструктура за 2 минуты:
Вам не нужно тратить рабочие часы DevOps-инженеров на установку Prometheus, развертывание баз данных для долгосрочного хранения метрик, настройку Alertmanager и ручное создание дашбордов. Вы получаете преднастроенные профессиональные панели Grafana и правила оповещений сразу после запуска легковесного агента.
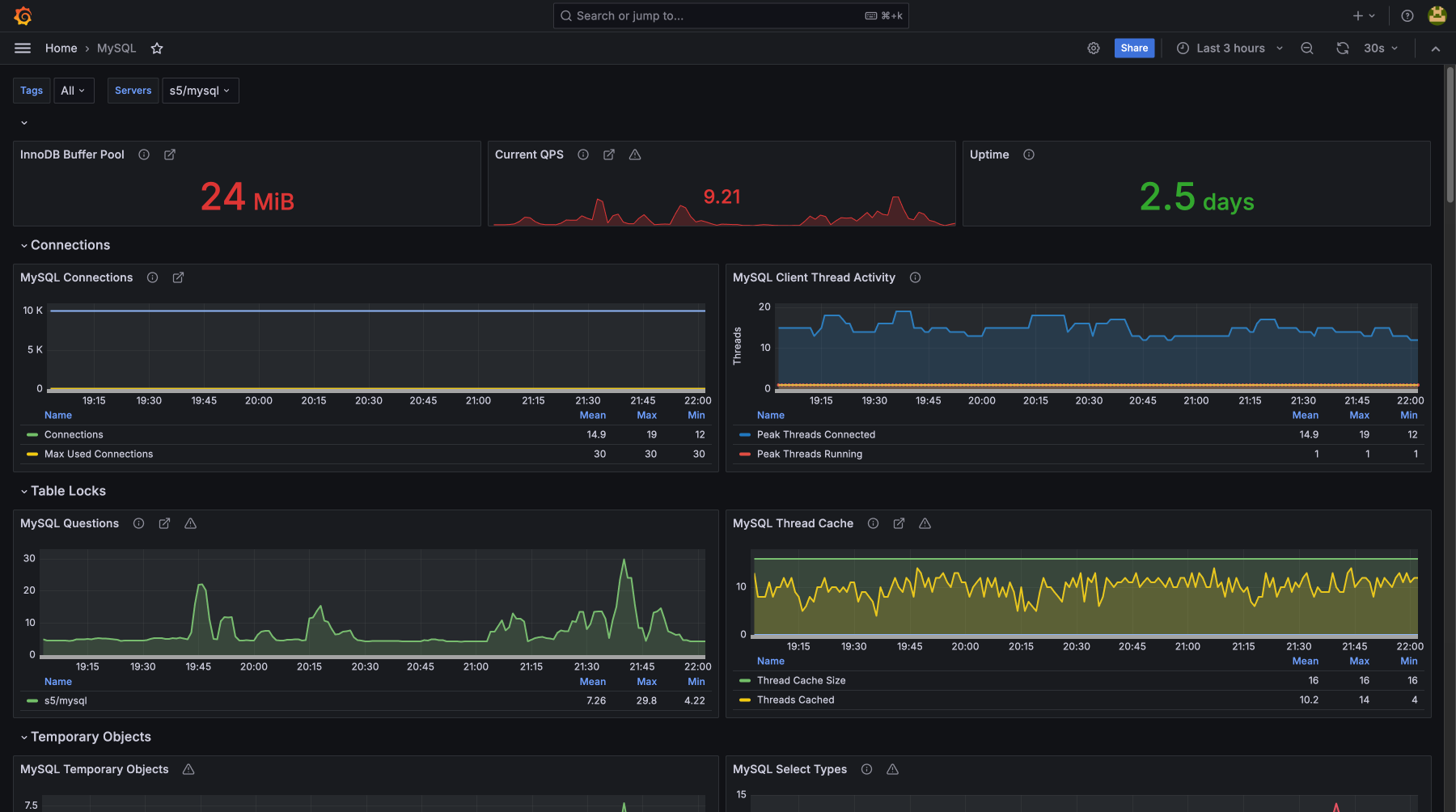
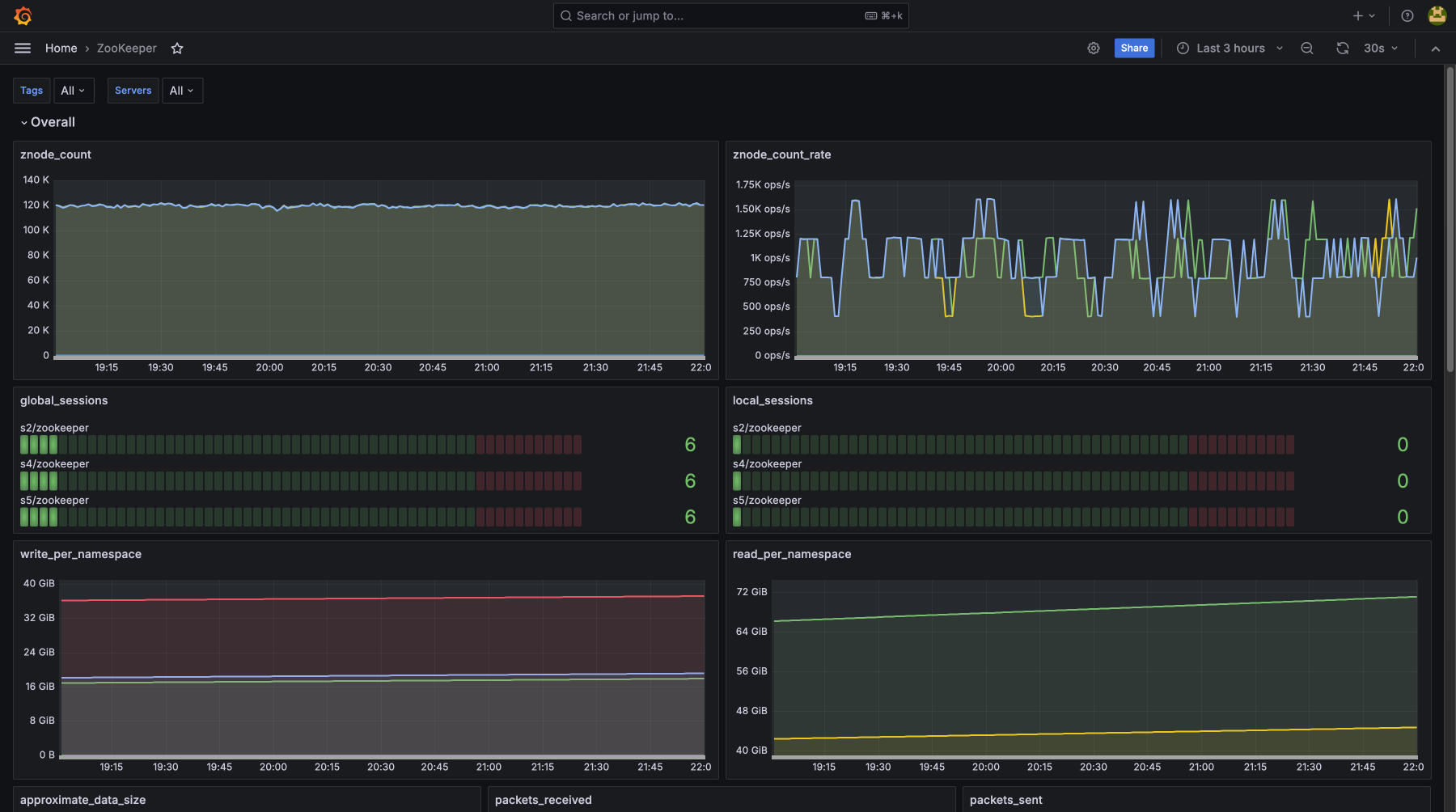
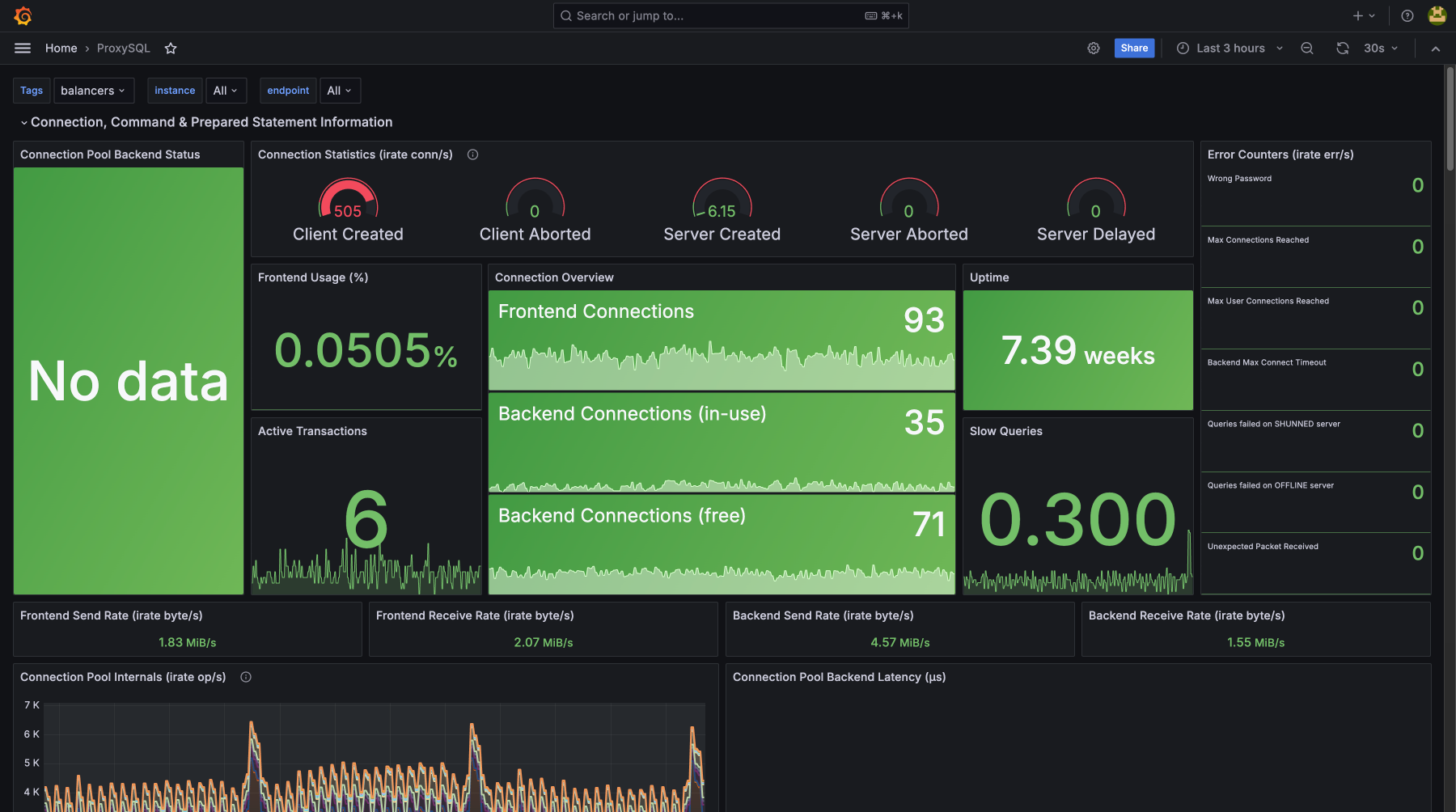
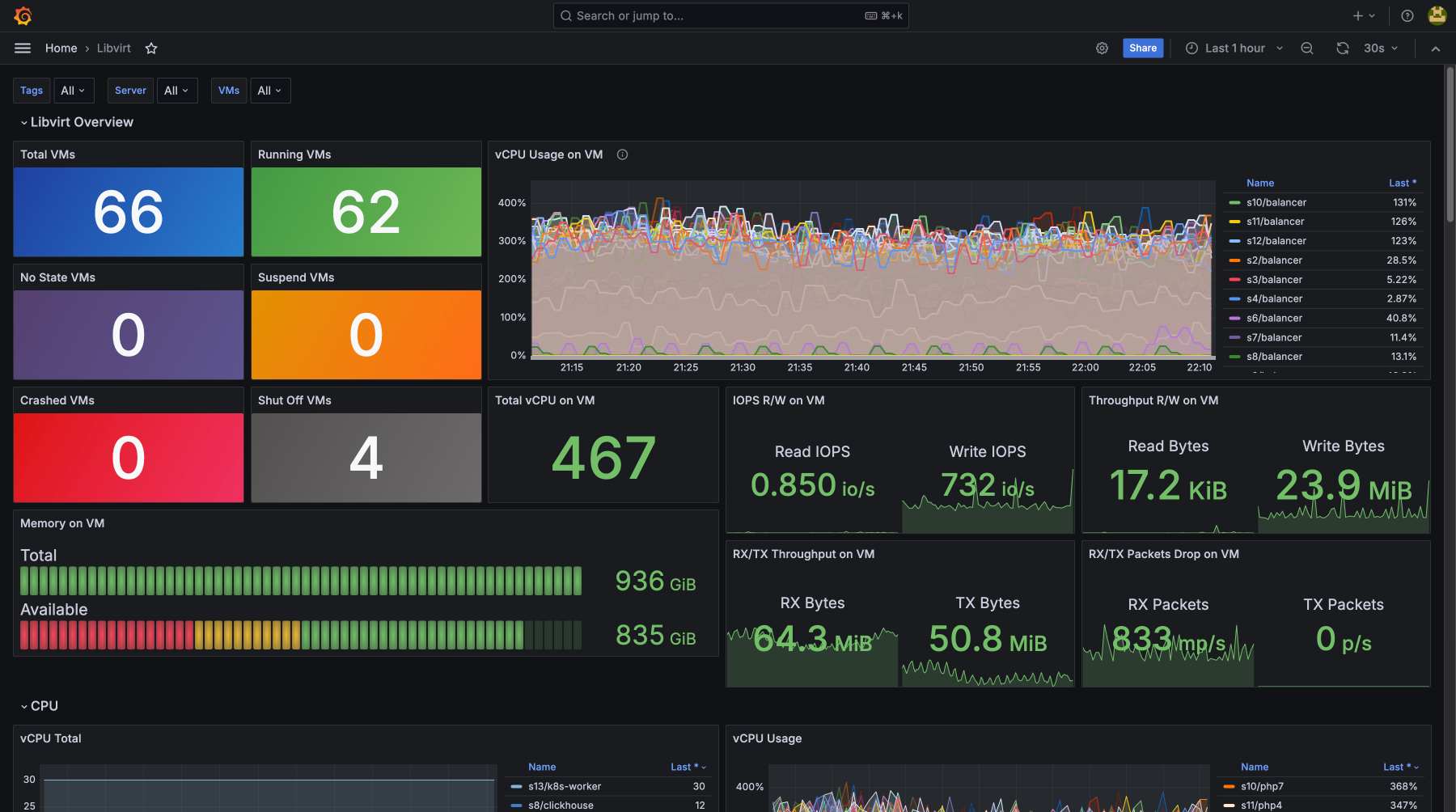
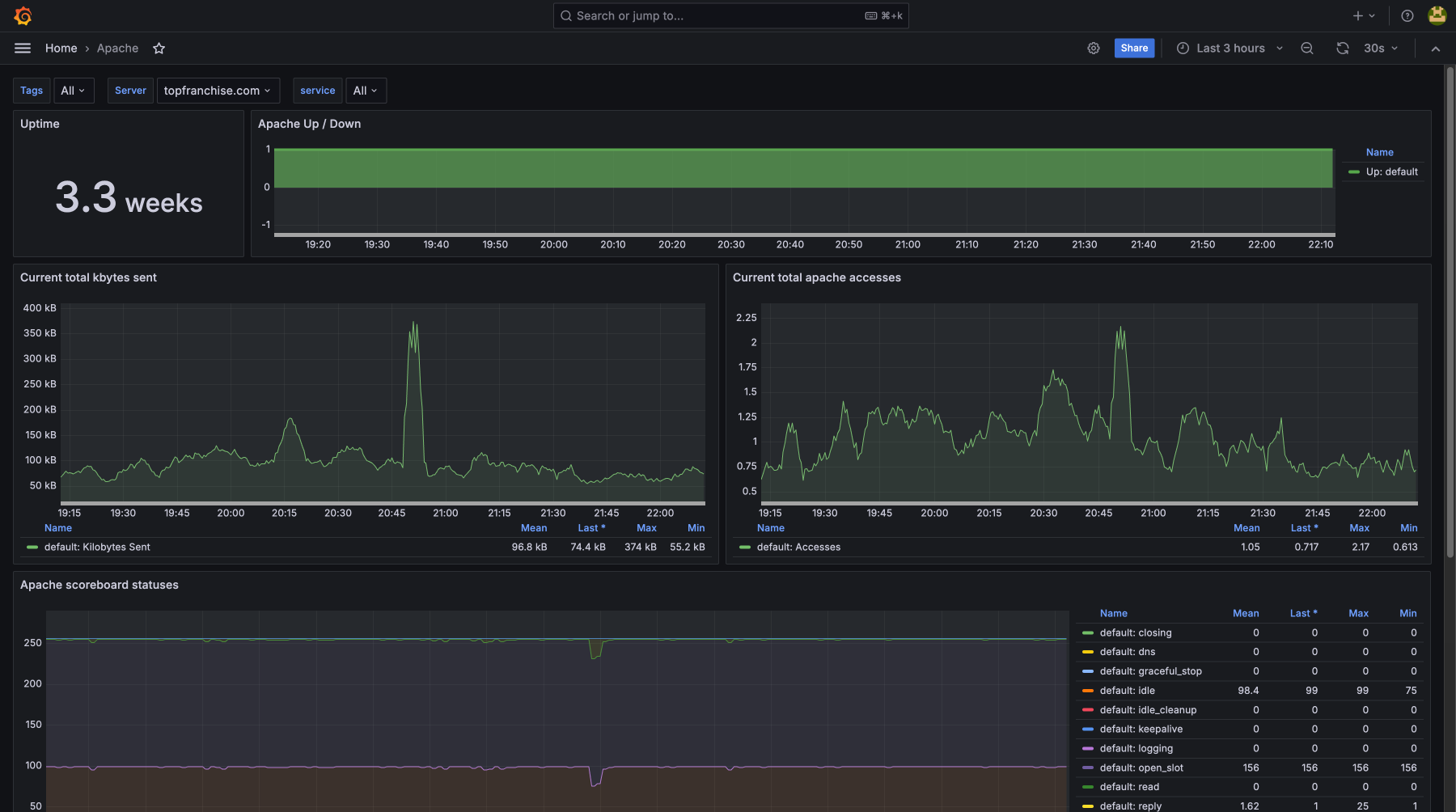
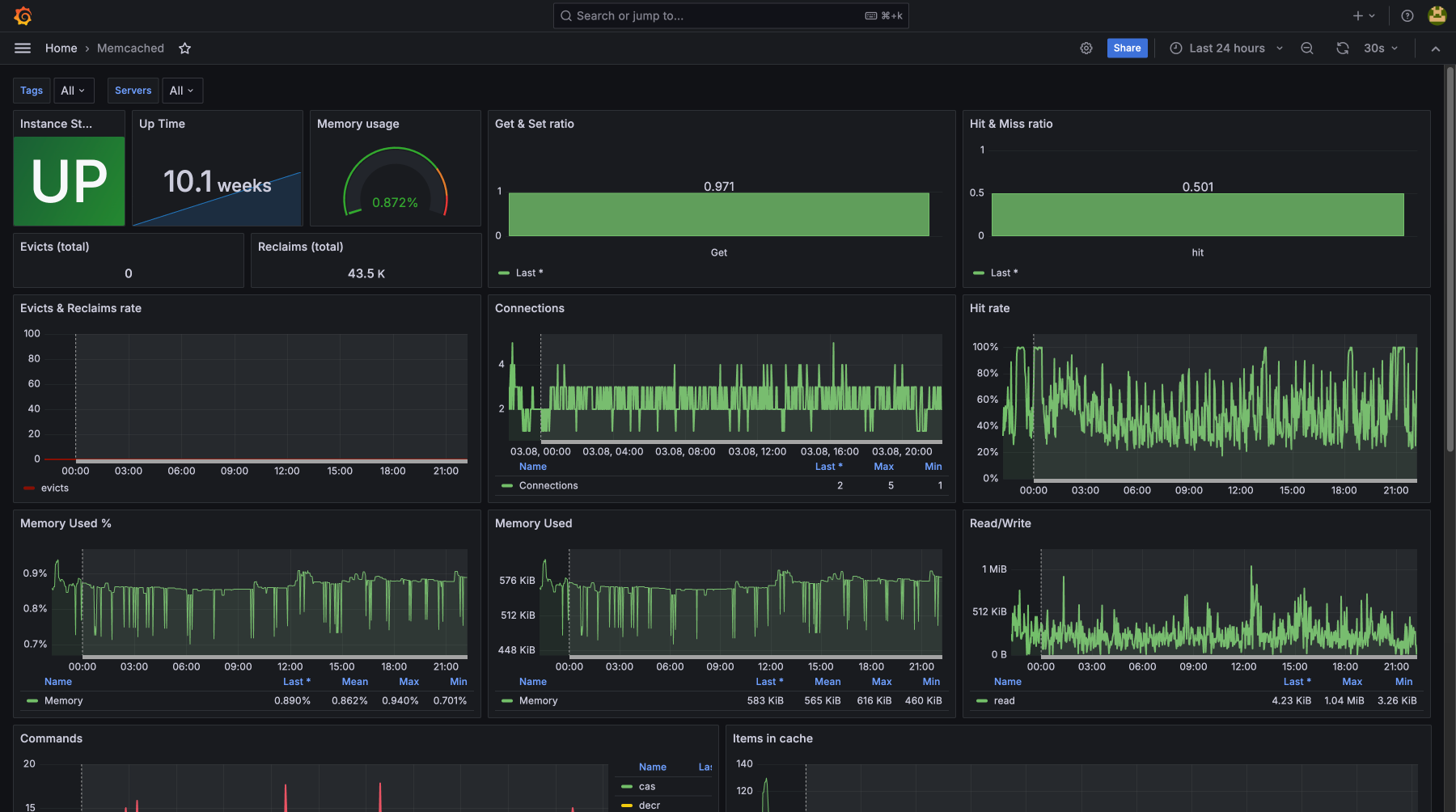
Стек технологий, который мы мониторим
- nginx
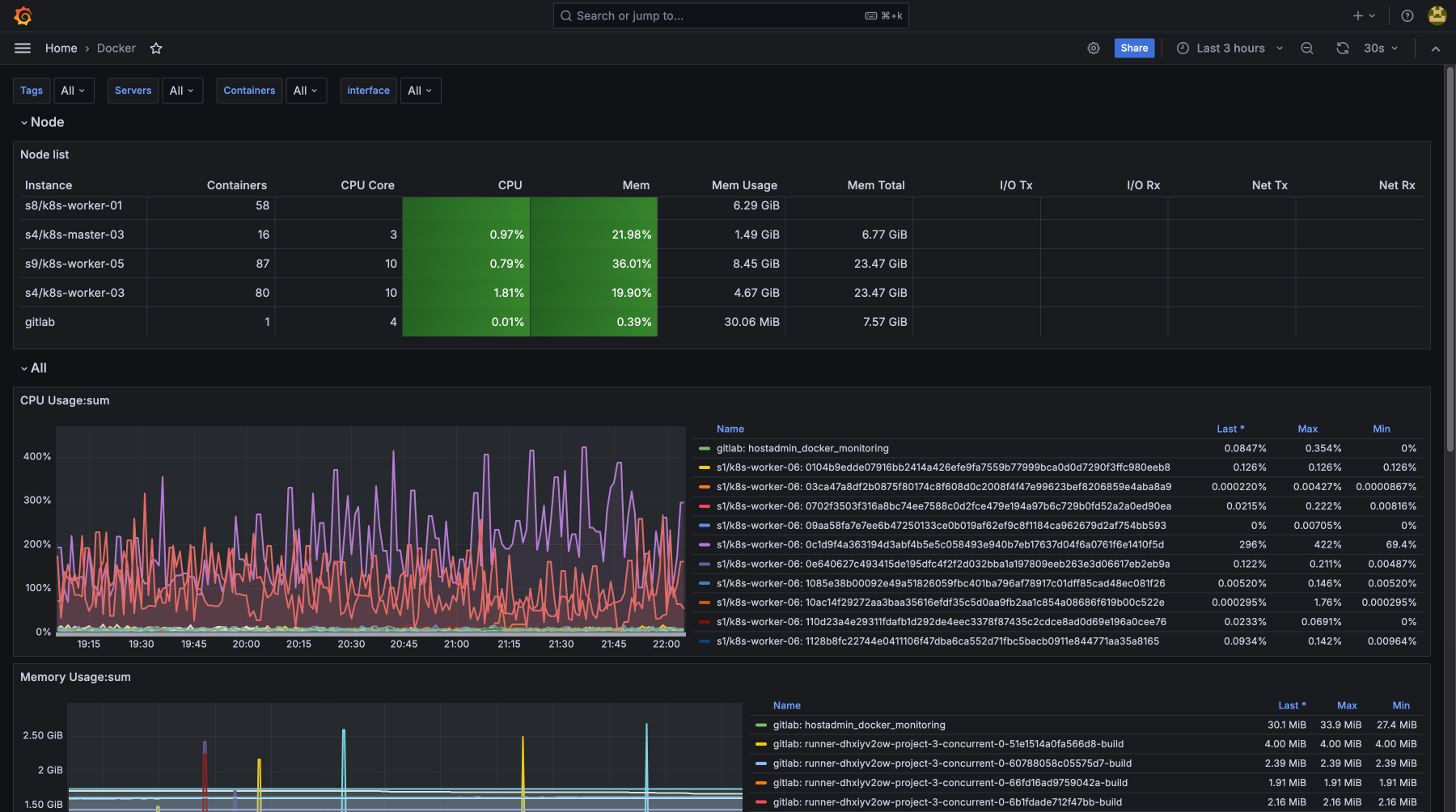
- docker
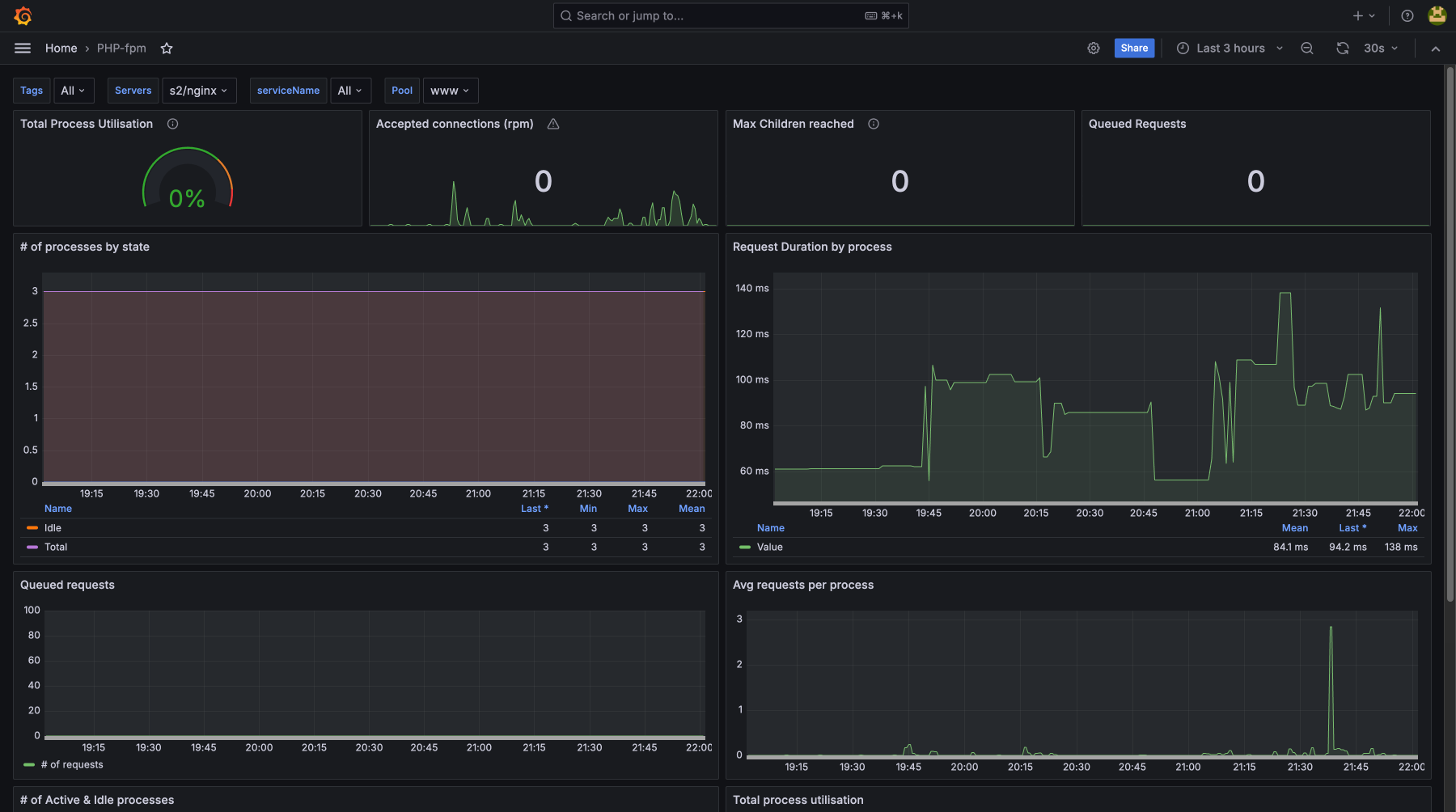
- php-fpm
- apache2
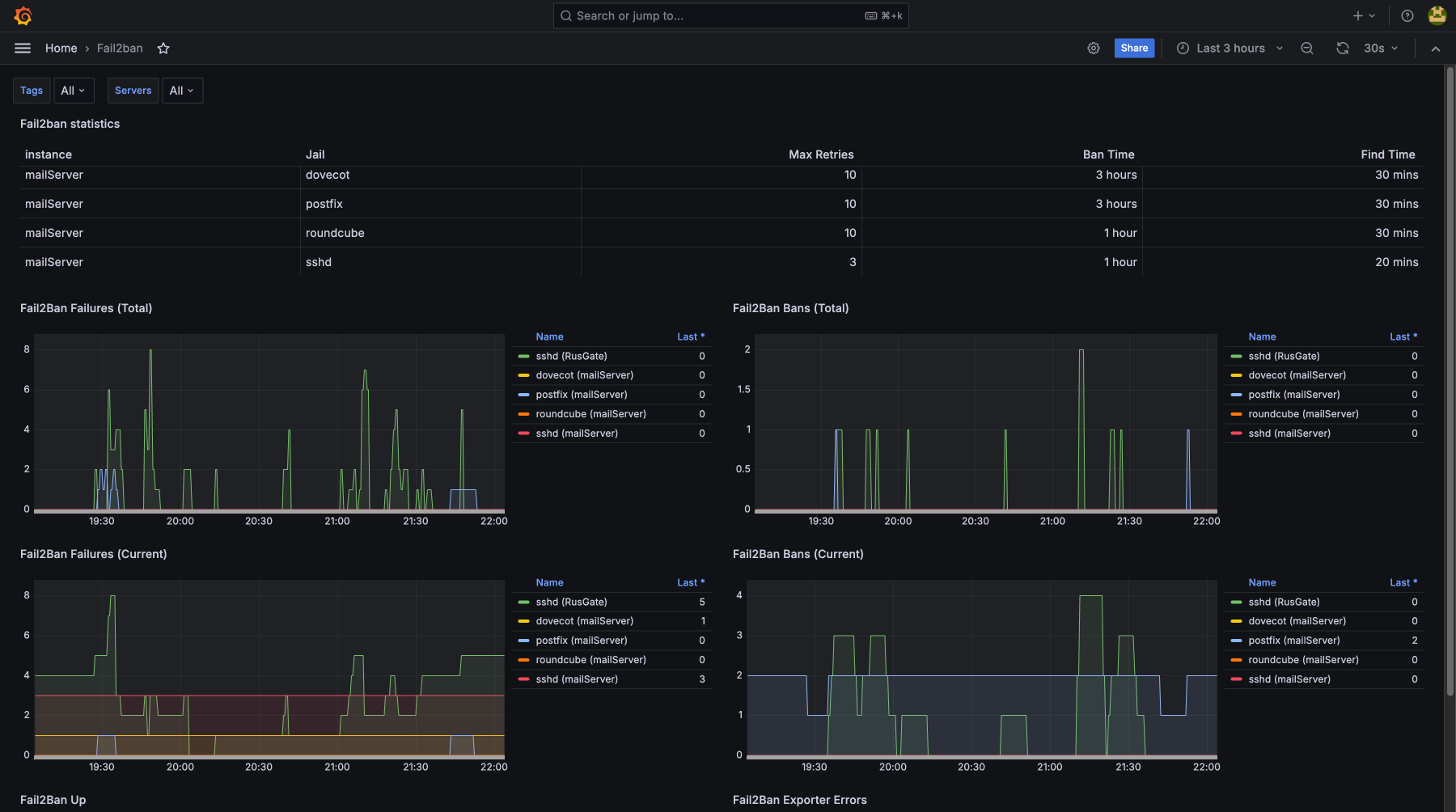
- fail2ban
- redis
- exim4
- mariadb
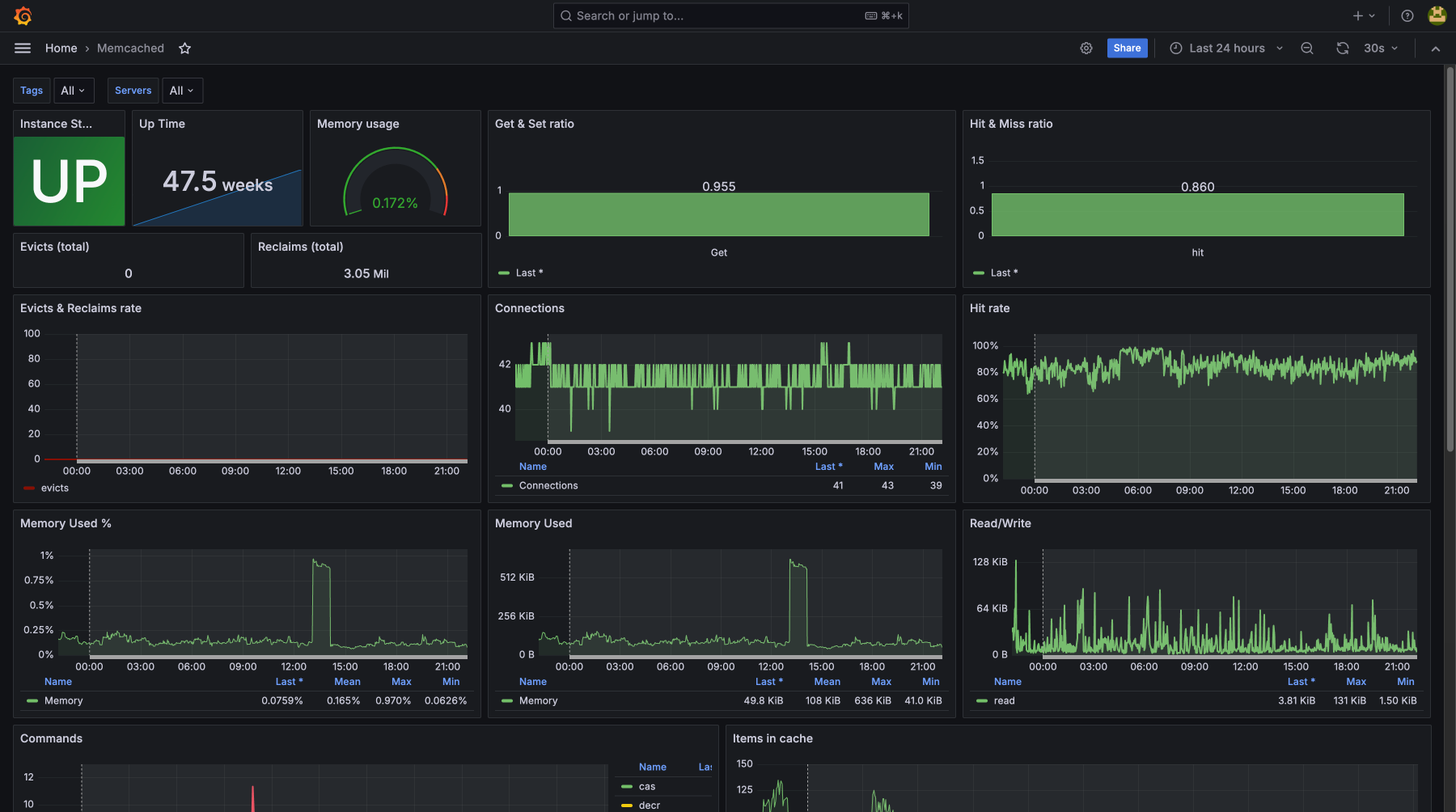
- memcached
- postgresql
- postfix
- mysql
- dovecot
- haproxy
- openvpn
- libvirt
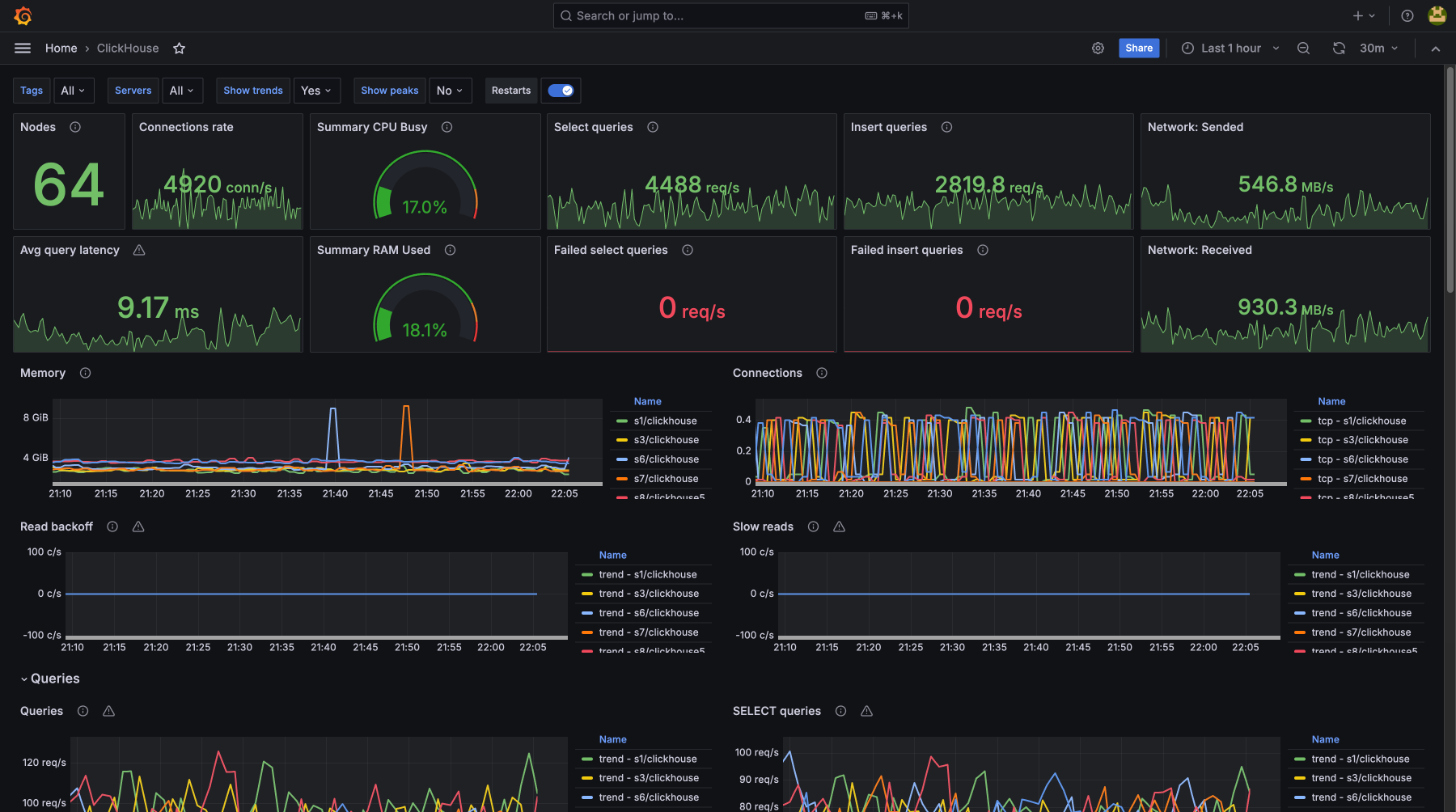
- clickhouse
- kubernetes
- clamav
- bind9
- percona-mysql-xtradb
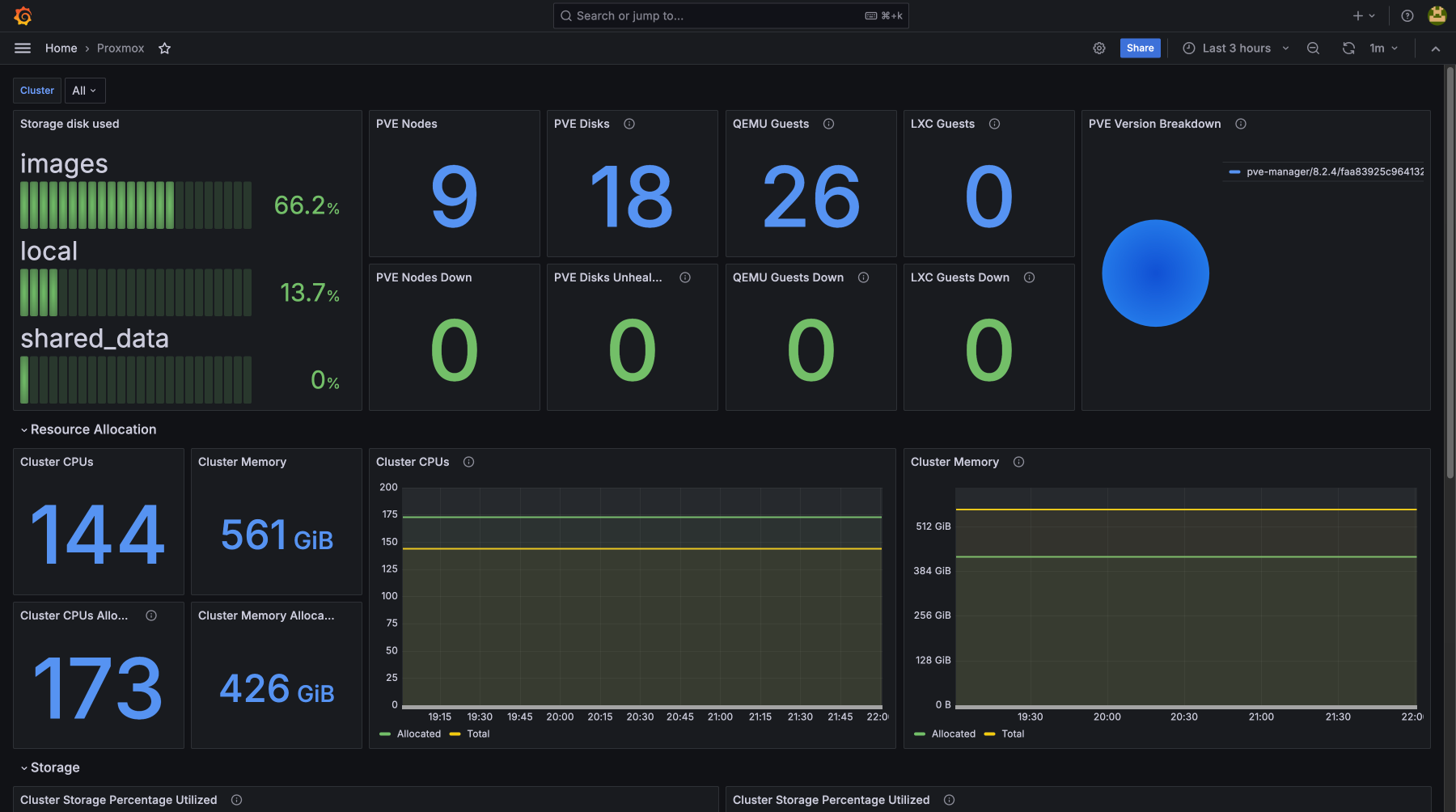
- mongodb
- proxmox
- lxc
- rabbitmq
- etcd
- gitlab
- ElasticSearch
- patroni
- proxysql
- PGbouncer
- vrrp
- wireguard
- apachenifi
- kafka
- danted
- squid
- sphinx
- Strongswan
- traefik
- varnish
- keepalived
- krakend
- proftpd
- docker-swarm
- 3proxy
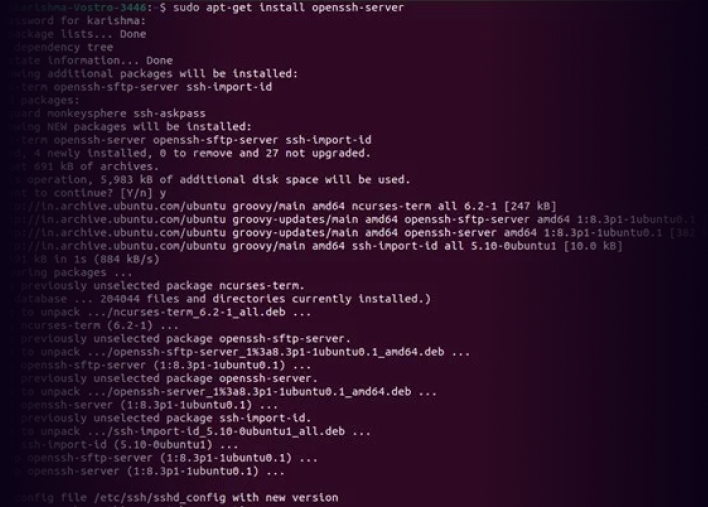
Собственные легковесные статические агенты: без опасности для вашей ОС
Статически скомпилированные бинарники:
Наши агенты сбора метрик (Prometheus exporters) скомпилированы статически в единые исполняемые файлы. Они не имеют внешних зависимостей и работают изолированно.
Никаких системных пакетов:
Мы не запускаем на вашем сервере команды установки пакетов (apt install, yum install и др.). Ваша операционная система остается кристально чистой, без риска нарушить зависимости вашего основного ПО.
Безопасный Push-метод:
Агент сам отправляет зашифрованные данные в наше облако по TLS-каналу. Вам не нужно открывать входящие порты на брандмауэре (Firewall) вашего сервера.
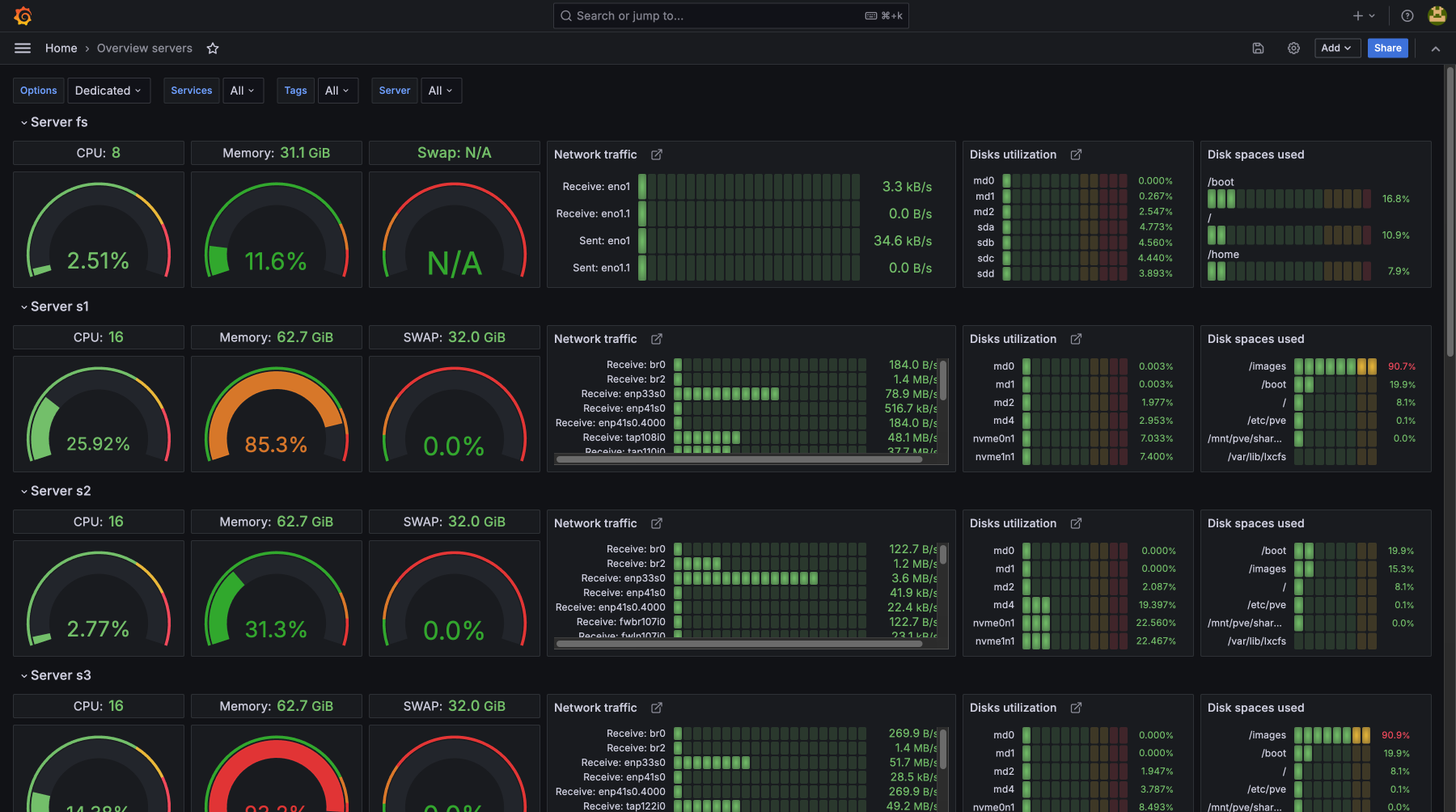
Контроль показателей сервера:
не только CPU, SWAP, память и диски
тотальный контроль над работой сервера, сайта, приложения
Контролируя загрузку CPU, использование памяти, дисковую утилизацию и сетевую активность, вы предотвращаете возможные сбои и устраняете узкие места. Мониторинг покажет, что есть проблемы до их критического проявления, для бесперебойной работы сервисов и минимизации простоев. Регулярное отслеживание метрик помогает оптимизировать ресурсы, улучшить производительность и получить нужный уровень безопасности и стабильности
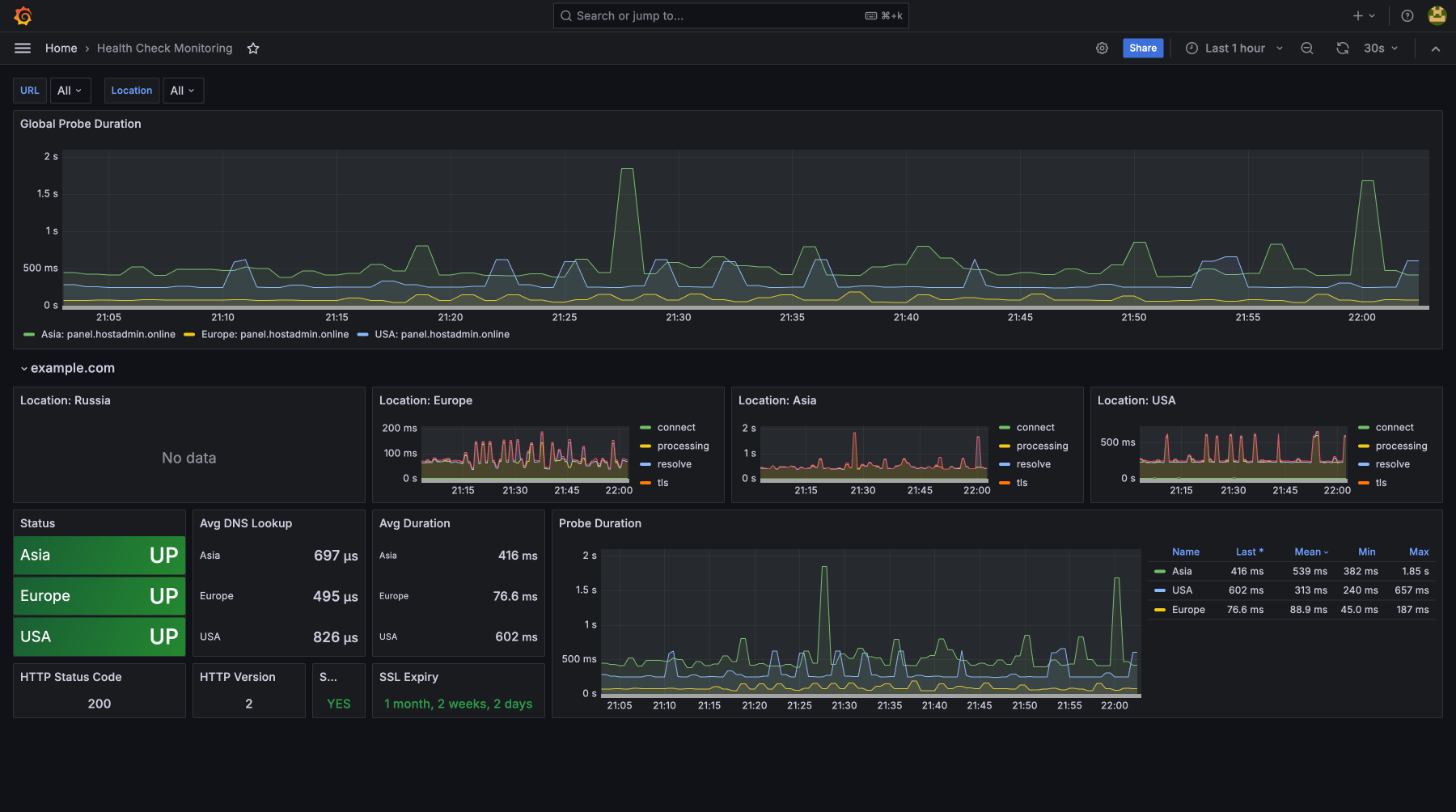
Воспользуйтесь услугами AI-Ассистента
Задавайте любые вопросы через Telegram и получайте ответы с инструкциями от AI.
Интерактивный DevOps-справочник по каждому инциденту
Получили алерт, но не сталкивались с такой ошибкой раньше? Просто спросите ИИ-Ассистента в чате: «Пришло уведомление [Текст ошибки]. Какие команды запустить для диагностики?». Он выдаст пошаговую инструкцию и команды для быстрого исправления сбоя.
Нужно развернуть новый сервис или оптимизировать старый? Спросите ассистента: «Как настроить ротацию логов для Nginx?» или «Дай оптимальный конфиг sysctl для высоконагруженного Postgres-сервера». Вы получите готовые конфигурационные файлы и команды.
ИИ избавляет от необходимости искать документацию или гуглить решения во время аварии, когда каждая минута простоя компании стоит денег.
Часто задаваемые вопросы
Если у вас остались вопросы, ознакомьтесь с ответами ниже или свяжитесь с нами.
Практически нет. Наши агенты написаны на Go и C, оптимизированы для высоконагруженных систем и потребляют минимум ресурсов: менее 0.5% CPU и до 20 МБ оперативной памяти. Все тяжелые вычисления по анализу данных происходят на стороне нашего облачного кластера.
Нет. Наша система работает по безопасной Push-модели. Агент сам собирает метрики локально и отправляет их в наше облако по исходящему шифрованному TLS-соединению. Вам не нужно открывать никаких входящих портов на вашем Firewall, инфраструктура остается полностью закрытой извне.
В наши агенты встроен легковесный кольцевой буфер памяти. При кратковременном обрыве связи метрики не теряются — они накапливаются локально и отправляются в наш облачный кластер сразу после восстановления соединения. При этом наш внешний кластер мгновенно зафиксирует отсутствие «пинга» от вашего сервера и незамедлительно пришлет вам алерт о потере связи с хостом.
По умолчанию базовый интервал сбора метрик составляет 60 секунд (1 раз в минуту) — этого достаточно для большинства стандартных задач. Для критически важных сервисов (например, продакшн-БД с высокой нагрузкой) вы можете уменьшить интервал опроса до 30 секунд или чаще прямо в конфигурационном файле агента.
Важный момент: вы можете гибко менять частоту сбора для каждого сервиса отдельно. Но учитывайте, что чем чаще собираются метрики, тем больше поток данных отправляется на наши серверы и тем быстрее расходуется ваша дисковая квота, что напрямую влияет на итоговую стоимость услуги мониторинга. Это позволяет вам точно балансировать между детальностью графиков и вашим бюджетом.
Нет, AI-Ассистент работает исключительно в режиме интерактивного технического консультанта и не имеет прямого доступа к управлению вашим сервером. Это гарантирует безопасность. Вы можете спросить его, как настроить ту или иную службу, или как действовать при получении конкретного алерта мониторинга, и он мгновенно выдаст вам точную пошаговую инструкцию и нужные консольные команды.
По умолчанию мы поддерживаем мгновенную отправку алертов в Telegram (групповые или приватные чаты).